
Batch processing
To collect data from multiple URLs with a single request, use a batch request. Batch requests share largely the same structure and cycle as asynchronous requests, but can perform up to 1,000 tasks in a single batch, and have a dedicated endpoint. To initiate a batch request, use the https://api.webit.live/api/v1/batch/web endpoint, such as in the example below:
curl -X POST 'https://api.webit.live/api/v1/batch/web' \
--header 'Authorization: Basic <credential string>' \
--header 'Content-Type: application/json' \
--data-raw '{
"requests": [
{ "url": "https://www.finance.com" },
{ "url": "https://www.travel.com" },
{ "url": "https://www.socialmedia.com" }
],
"storage_type": "s3",
"storage_url": "s3://Your.Repository.Path/",
"callback_url": "https://your.callback.url/path"
}'import requests
url = 'https://api.webit.live/api/v1/batch/web'
headers = {
'Authorization': 'Basic <credential string>',
'Content-Type': 'application/json'
}
data = {
"requests": [
{ "url": "https://www.finance.com" },
{ "url": "https://www.travel.com" },
{ "url": "https://www.socialmedia.com" }
],
"storage_type": "s3",
"storage_url": "s3://Your.Repository.Path/",
"callback_url": "https://your.callback.url/path"
}
response = requests.post(url, headers=headers, json=data)
print(response.status_code)
print(response.json())Setting GCS/AWS access permissions
GCS Repository Configuration
In order to use Google Cloud Storage as your destination repository, please add Nimble’s system user as a principal to the relevant bucket. To do so, navigate to the “bucket details” page in your GCP console, and click on “Permission” in the submenu.

Next, past our system user [email protected] into the “New Principals” box, select Storage Object Creator as the role, and click save.

That’s all! At this point, Nimble will be able to upload files to your chosen GCS bucket.
S3 repository configuration
In order to use S3 as your destination repository, please give Nimble’s service user permission to upload files to the relevant S3 bucket. Paste the following JSON into the “Bucket Policy” (found under “Permissions”) in the AWS console.
Follow these steps:
1. Go to the “Permissions” tab on the bucket’s dashboard:

2. Scroll down to “Bucket policy” and press edit:

3. Paste the following bucket policy configuration into your bucket:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::744254827463:user/webit-uploader"
},
"Action": [
"s3:PutObject",
"s3:PutObjectACL"
],
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/*"
},
{
"Sid": "Statement2",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::744254827463:user/webit-uploader"
},
"Action": "s3:GetBucketLocation",
"Resource": "arn:aws:s3:::YOUR_BUCKET_NAME"
}
]
}Important: Remember to replace “YOUR_BUCKET_NAME” with your actual bucket name.
Here is what the bucket policy should look like:

4. Scroll down and press “Save changes”

S3 Encrypted Buckets
If your S3 bucket is encrypted using an AWS Key Management Service (KMS) key, additional permissions to those outlined above are also needed. Specifically, Nimble's service user will need to be given permission to encrypt and decrypt objects using a KMS key. To do this, follow the steps below:
Sign in to the AWS Management Console and open the AWS Key Management Service (KMS) console.
In the navigation pane, choose "Customer managed keys".
Select the KMS key you want to modify.
Choose the "Key policy" tab, then "Switch to policy view".
Click "Edit".
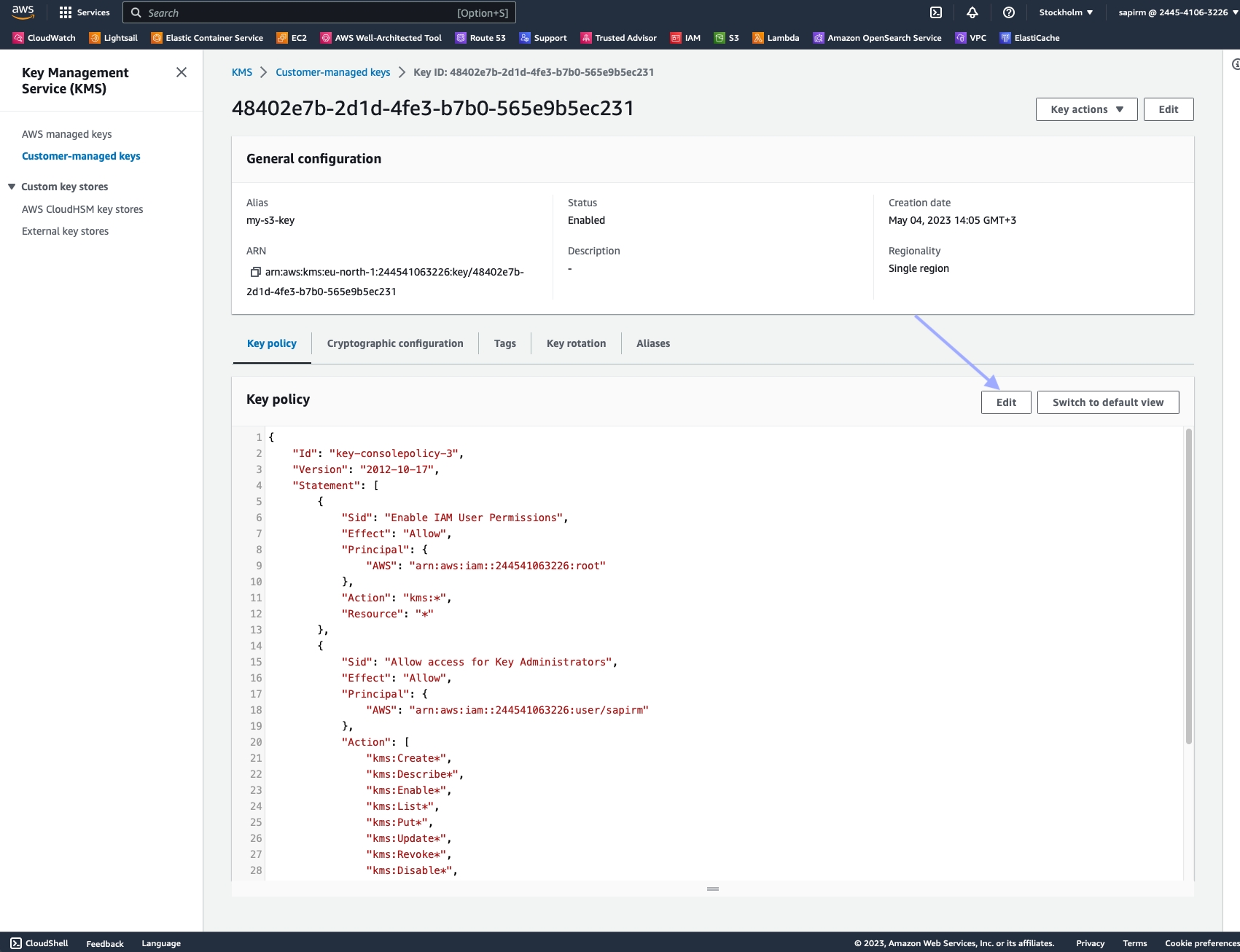
Add the following statement to the existing policy JSON, ensuring it's inside the Statement array:
{
"Version": "2012-10-17",
"Id": "example-key-policy",
"Statement": [
// ... your pre-existing statements ...
{
"Sid": "Allow Nimble APIs account",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::744254827463:user/webit-uploader"
},
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "*"
},
]
}Click "Save changes" to update the key policy.
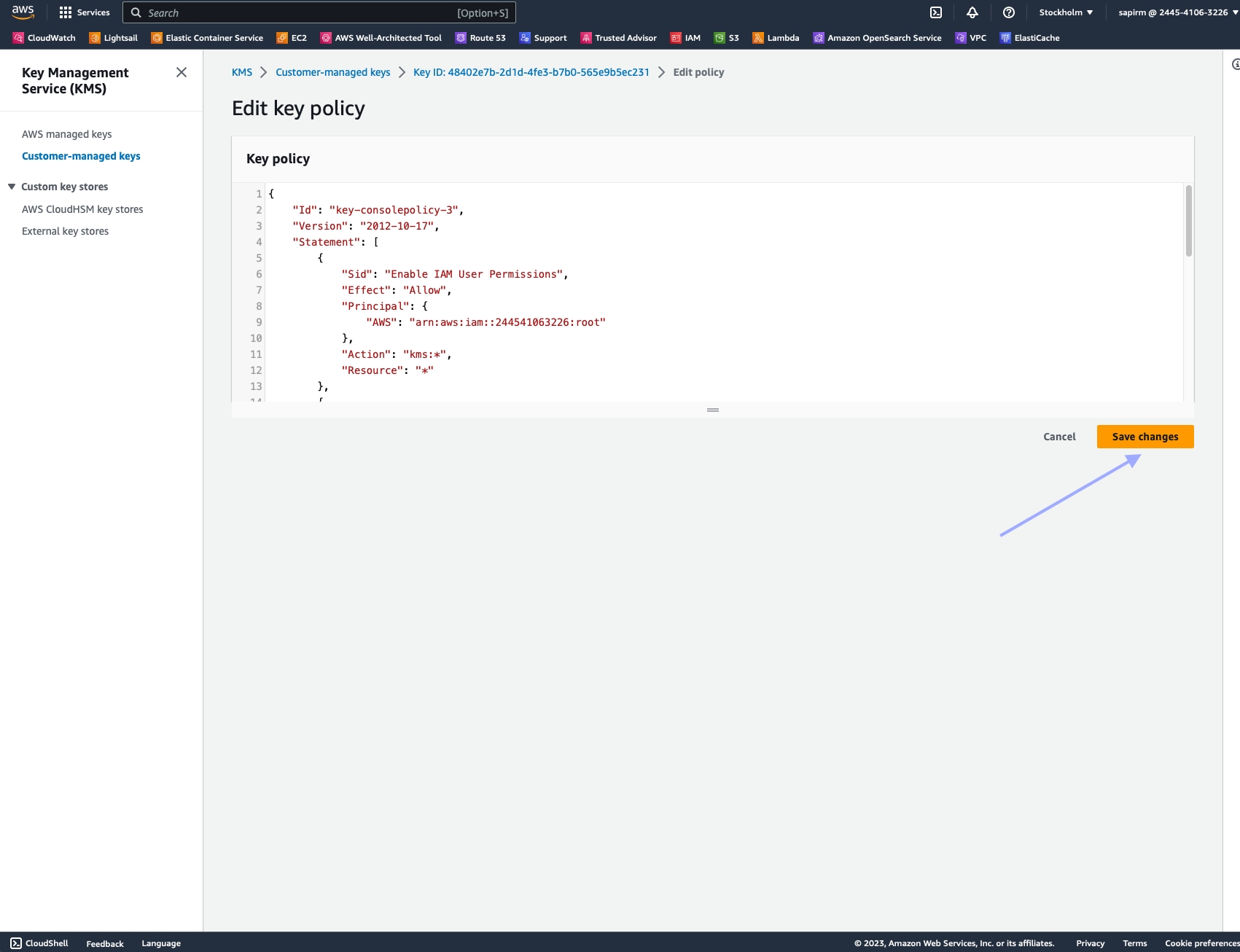
That's it! You've now given Nimble APIs permission to encrypt and decrypt objects, enabling access to encrypted buckets.
Tasks in a batch request all share the same request settings, such as location, rendering, parsing, etc.
Once a batch request is initiated, a batch_id is produced that can be used to check the progress/status of a batch or retrieve a summary of the batch. Every time a task within the batch is completed, an individual completion notification is sent to the provided callback URL.
For a more in-depth walkthrough on batch requests, please see the API Functions Documentation.
Last updated