
Network Capture
Overview
In the past, when a webpage was requested, all of the information presented on the page would be loaded and presented together as a single package. All the HTML, images, Javascript, CSS, and other resources were an inherent part of the webpage itself.
However, over time businesses discovered many advantages in loading some data dynamically. Retail platforms like Amazon run dynamic pricing algorithms that adjust the price of each product in real time. Search Engines use lazy-loading strategies instead of pagination - loading new information as the user scrolls without reloading the page.
A common technical approach to managing and loading information dynamically in this manner involves creating internal APIs. Businesses use internal APIs - which are not explicitly exposed to users - to request information and then add it to the presented webpage.
In the below example, we use Chrome's Developer Tools to demonstrate how Expedia loads data dynamically from an internal API:
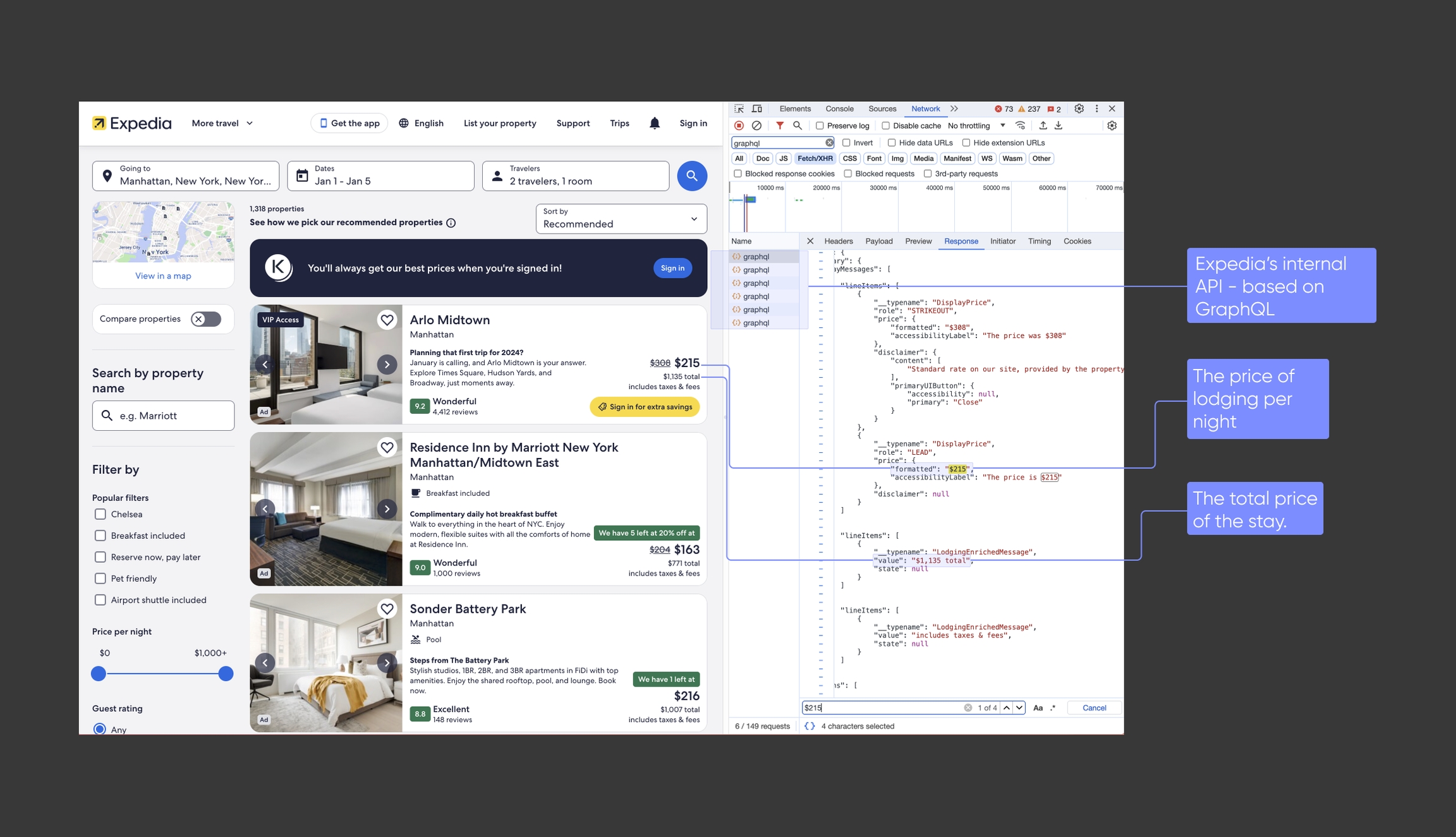
By capturing these internal API calls, developers can directly access key data in machine-readable formats - typically JSON. This circumvents the need to parse the desired data out of HTML.
Furthermore, by understanding the inputs of these internal APIs, developers over time can learn how to interact with them directly, with no need to go through the public-facing webpages.
What?
Network Capture Feature allow users to capture internal API calls to collect lazy-loaded/dynamic data and to interact with it directly, with no need to go through the public-facing webpages.
To capture internal website APIs, the user could filter the desired calls based on:
Exact match filter - based on internal call URL and method (GET/POST/Any)
Containing a match - based on internal call URL and method (GET/POST/Any)
Resource Type - based on the internal API resource type (Fetch/XHR/Stylesheet/Script/etc.)
Why?
Access to Dynamic and Lazy-Loaded Content: Many websites today load data asynchronously after the initial page load, often in response to user actions or as the user scrolls down the page. The network capture feature allows you to intercept these internal API calls and capture this dynamic content directly. This is essential for extracting data that isn't immediately available on the webpage at load time but is instead loaded dynamically as needed.
Direct Interaction with APIs: By capturing internal API calls, you can bypass the need to interact with the user interface of public-facing webpages. This direct interaction with APIs is not only faster but also more efficient as it eliminates the overhead associated with rendering the UI. It allows for more precise and targeted data extraction, directly from the source of the data.
Efficiency and Speed: Interacting with internal APIs is generally more efficient than scraping content from fully rendered webpages. APIs are designed to transmit data in a structured format, typically JSON, which is easier and quicker to parse compared to extracting information from HTML content. This increases the overall speed and efficiency of the data collection process.
Reduced Overhead and Lower Resource Usage: Since you are bypassing the graphical elements of a website and focusing only on the data transfer, the network capture feature reduces the computational load on your system. This leads to lower resource usage and can significantly decrease the costs associated with data extraction, particularly at scale.
Enhanced Data Accuracy and Reliability: API data is typically more structured and less prone to errors compared to data scraped from the frontend of a website. By capturing data directly from API calls, you reduce the likelihood of scraping errors associated with frontend changes, ensuring higher data accuracy and reliability.
Additional Information
Supported by real-time, asynchronous, and batch requests.
Supported Endpoints: Web
Requires page rendering
While no one field of
network_captureis required, sending at least one field is required.If a
urlfilter is defined, thevaluefield must be set as well.
Network Capture will not function if rendering is not enabled in the request. Please be sure to set render:true in order for it to function correctly.
Example Request
Requests can be captured by using the network_capture field, which receives a JSON array that can include one or more filters. Each filter specifies which requests should be collected for later inspection.
url
Required when filtering by URL
Object | Describes the URL(s) to filter and capture, for more info see Filtering by URL
resource_type
Required when filtering by resource type
List [Enums] | set all required resource type to filter, for more info see Filtering by Resource Type
method
Optional (default = Any)
Enum | HTTP method should be filtered for. Examples: GET, POST, PUT.
validation
Optional (default = false)
Bool | Determine whether to run content validation on the responses or not
The below example demonstrates two simple network capture filters, and how they are performed:
Last updated